در تصمیمگیریهای کسبوکار بسیار اهمیت دارد که مدیران بتوانند رابطه علّی را درست تشخیص دهند. میتوان گفت در بیشتر موارد مدیریت یعنی ایجاد تغییر در چیزهایی که تحت کنترل است بهمنظور آنکه روی چیزهای دیگری که تحت کنترل نیست، اثر گذاشت تا به نتیجه دلخواه رسید. برای مثال یک مدیر بودجه تبلیغات سازمان خود را افزایش میدهد (آنچه تحت کنترل است) به امید آنکه فروش بیشتری ایجاد کند (نتیجه دلخواه). یا دستمزد سال آتی کارمند خود را افزایش میدهد (آنچه تحت کنترل است) تا انگیزه او را برای کار کردن بیشتر کند (نتیجه دلخواه). پس نکته مهم آن میشود که یک مدیر بتواند علت پدیدهها را درست تشخیص دهد.
اما در دنیای واقعی همیشه مسائل آنطور که مینماید، نیست. در مقاله “چرا مدیران باید تفاوت بین همبستگی و رابطه علّی را بدانند؟” با ارائه مثالهای متنوعی از دنیای واقعی توضیح دادم چگونه ممکن است دلایل بروز یک پدیده اشتباه تشخیص داده شود. من در این مقاله فرض میکنم، خواننده مقاله مذکور را مطالعه کرده است و به این موضوع میپردازم که بر چه اساسی وجود رابطه علّی را میتوان تشخیص داد.
مدیران برای آنکه بتوانند رابطه علّی را بین پدیدهها بهدرستی تشخیص دهند باید به سه معیار زیر توجه کنند:
وجود رابطه (Association)،
ترتیب رخداد وقایع (Time Order)، و
نبود رابطه جعلی (Non-Spuriousness).
وجود رابطه
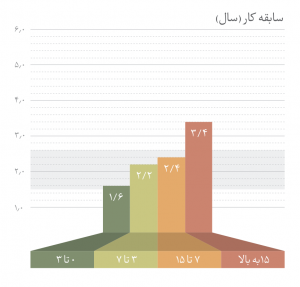
در گام اول باید نشان داد بین دو متغیر رابطهای وجود دارد. اگر افزایش یک متغیر با افزایش و یا کاهش دیگری همراه است، میتوان گفت بین این دو متغیر رابطه وجود دارد. برای مثال در بسیاری از موارد دیده میشود هر چه افراد تجربه کاری بیشتری در صنعت داشته باشند، دستمزد سالیانه بیشتری دریافت میکنند (البته این اثر ممکن است از یکمیزان تجربه کاری بیشتر، کمرنگ شود). پس باید دید آیا دادهها وجود چنین حدسی را تائید میکنند یا خیر. برای نمونه من رابطه بین سابقه کار و حقوق سالیانه را برای شاغلین حوزه حسابداری، حسابرسی و مدیریت مالی از گزارش حقوق و دستمزد سال ۱۳۹۵ ایران تلنت (Iran Talent) استخراج کردم و در شکل-۱ نشان دادم. نمودار نشان میدهد برای این گروه از شاغلین هرچه تجربه کاری افزایش یابد، میانگین دستمزد سالیانه بیشتر میشود.
در این نمودار تجربه کاری به شکل یک متغیر رستهای (Categorical) و میزان حقوق و دستمزد به شکل عددی (Numerical) اندازهگیری شده است. این یعنی میزان تجربه کاری در چند دسته تقسیم شده، درحالیکه میزان دستمزد (بر حسب میلیون تومان) میتواند هر عددی را به شکل پیوسته به خود بگیرد.
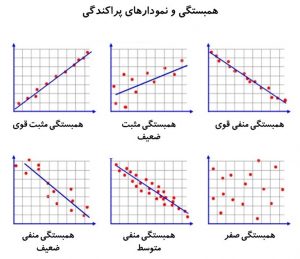
زمانی که هر دو متغیر عددی هستند، شدت رابطه خطی را میتوان بهصورت کمّی با ضریب همبستگی (Correlation Coefficient) سنجید. ضریب همبستگی همواره عددی بین ۱ و ۱- است. این ضریب دو بخش دارد: مقدار عددی و علامت. مقدار عددی نشان میدهد چقدر رابطه خطی بین دو متغیر قدرتمند است. علامت نشان میدهد جهت این رابطه مثبت است یا منفی.
اگر ضریب همبستگی مثبت باشد، به این مفهوم است که افزایش در مقادیر یک متغیر با افزایش در مقادیر متغیر دیگر همراه است. همینطور کاهش در مقادیر یک متغیر با کاهش در مقادیر متغیر دیگر همراه است. در این حالت اگر نمودار پراکندگی دو متغیر رسم شود، میتوان خطی با شیب مثبت را از بین نقاط برازش داد (شکل-۲). به همین ترتیب اگر ضریب همبستگی منفی باشد، میتوان خطی با شیب منفی را از بین نقاط برازش داد (شکل-۲).
هرچه مقدار مطلق ضریب همبستگی (صرفنظر از علامت) به ۱ نزدیک باشد، نشان میدهد شدت رابطه خطی بین دو متغیر قویتر است. در مقابل ضریب همبستگی نزدیک صفر نشان میدهد که رابطه خطی بسیار ضعیفی بین دو متغیر برقرار است.
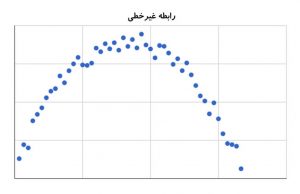
اگر بین دو متغیر رابطه غیرخطی برقرار باشد، همچنان این امکان وجود دارد ضریب همبستگی نزدیک صفر باشد که نشاندهنده نبود رابطه خطی بین دو آن است (شکل-۳). به همین دلیل در هنگام تحلیل بهتر است نمودار پراکندگی بین متغیرها رسم شود تا به وجود این روابط پی برد.
برای آنکه از وجود رابطه بین دو متغیر مطمئن شویم، تنها به میزان شدت و ضعف رابطه (انداز ضریب همبستگی) نباید اطمینان کرد بلکه باید به سطح معنیداری آماری نیز توجه کرد. بحث بیشتر در این مورد را میتوانید در مقاله “ضریب همبستگی چیست و چه کاربردی دارد؟” دنبال کنید.
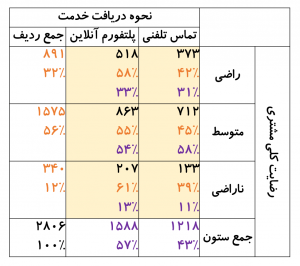
در حالتی که هر دو متغیر به شکل رستهای اندازهگیری شدهاند، معمولاً دادهها را در جدول متقاطع (Cross Tabulation) نشان میدهیم. شکل-۴ نتایج یک نظرسنجی را در قالب جدول متقاطع نشان میدهد. در این مثال شرکتی برای ارائه خدمات پشتیبانی مشتریان علاوه بر روش فعلی (تماس تلفنی)، پلتفرم آنلاین جدیدی را عرضه کرده است. شرکت تمایل دارد ببینید آیا بین استفاده از این دو روش و رضایت کلی مشتریان از دریافت خدمات پشتیبانی رابطهای وجود دارد یا خیر. در این مثال هر دو متغیر رستهای هستند؛ روش دریافت خدمت دارای دو حالت (تماس تلفنی یا پلتفرم آنلاین) و رضایت کلی مشتری دارای سه حالت (راضی، متوسط، ناراضی) است.
برای نمونه جدول نشان میدهد از ۱۲۱۸ نفری که در این نظرسنجی خدمات پشتیبانی را از طریق تماس تلفنی دریافت کردند، ۳۷۳ نفر معادل ۳۱ درصد از دریافت خدمت راضی بودند. همچنین میتوان گفت از بین ۸۹۱ نفری که در این نظرسنجی بیان کردند از دریافت خدمات پشتیبانی راضی هستند، ۳۷۳ نفر معادل ۴۲ درصد خدمات پشتیبانی را از طریق تماس تلفنی دریافت کردند.
یک روش مرسوم برای تحلیل جدول متقاطع، روش تحلیل کای-دو (Chi-Square Analysis) است. هدف آن است که بفهمیم آیا میتوانیم بگوییم استفاده از دو روش متفاوت دریافت خدمت به لحاظ آماری اثر معنیداری روی سطح رضایت مشتریان گذاشته است. تحلیل آماری برای این مثال نشان میدهد برای سطح معنیداری ۰٫۰۵ نمیتوان چنین نتیجهای گرفت. بنابراین نمیتوان گفت رابطهای بین روش دریافت خدمت و رضایت کلی مشتری از دریافت خدمت وجود دارد.
ترتیب رخداد وقایع
زمانی که از وجود رابطه مطمئن شدیم، توجه خود را به ترتیب زمانی متغیرهای موردنظر جلب میکنیم. اگر متغیر عامل یا مستقل (Independent Variable) بخواهد علت متغیر وابسته (Dependent Variable) باشد، منطقاً باید قبل از آن رخ دهد. بهعبارتدیگر، دلیل قبل از معلول باید رخ دهد. در حالت ایدئال از طریق آزمایش کنترلشده تصادفی (Randomized Controlled Experiment) میتوان به این موضوع پی برد. در آزمایش کنترلشده تصادفی سعی میکنیم بهدقت متغیرهای عامل را کنترل کنیم و سپس اثر آنان را روی خروجی موردنظر بسنجیم. به این شکل میتوان ترتیب رخداد وقایع را تنظیم کرد.
شاید خواننده استدلال کند در دنیای واقعی کسبوکار بهسختی میتوان اثر متغیرها را کنترل کرد. من با چنین استدلالی همدلی دارم. ولی بدترین حالت این است که ما خودمان شرایط را بهگونهای ایجاد کنیم که تداخل متغیرها اجازه اندازهگیری اثر آنان را ندهد. برای مثال در حوزه بازاریابی و ترویج من بارها دیدم که شرکتها همزمان چندین اقدام را انجام میدهند. وقتی شرکتی در یکزمان کوپن تخفیف در سطح گسترده به مشتریانش میدهد، حمل رایگان محصول را بهعنوان یک امتیاز پیشنهاد میدهد و یک کمپین تبلیغاتی در قالب مسابقه برگزار میکند، نمیتواند اثرات مجزای این فعالیتها را بر میزان فروش اندازهگیری کند. بهاینترتیب شرکت نمیفهمد سرمایهگذاری روی هر یک از این روشها چقدر برایش عایدی ایجاد میکند. شاید درنهایت شرکت از همه این روشها استفاده کند ولی حداقل برای دوره آزمایشی باید تا جای ممکن اثر بقیه رخدادها را کنترل کند.
ممکن است همواره مدیران این امکان را نداشته باشند که از طریق آزمایش کردن در کسبوکار به ترتیب رخداد وقایع پی ببرند. در این حالت تکیهبر منطق، استفاده از تجارب دیگران یا نتایج تحقیقات انجامشده میتواند به آنان در این امر کمک کند. پیام اصلی این است که یک مدیر هوشمند همواره در مورد جهت رابطه علی تأمل میکند و بهسرعت نتیجهگیری نمیکند؛ آیا مطمئن هستیم الف موجب ب شده یا شاید ب عامل الف شده و یا شاید متغیر سومی هر دو را هدایت میکند. در این مورد در مقاله “چرا مدیران باید تفاوت بین همبستگی و رابطه علّی را بدانند؟” همراه با مثالهایی بحث کردهام.
نبود رابطه جعلی
این امکان هست که دو متغیر همزمان باهم ارتباط داشته باشند، یکی قبل از دیگری رخ دهد ولی هیچ رابطه علّی بین آن دو وجود نداشته باشد. یک نمونه از وجود رابطه جعلی، رابطه بین سایز کفش کودکان و میزان دانش آنان است؛ هرچه سایز کفش کودک بزرگتر باشد دانش بیشتری دارند. واضح است که سایز کفش عامل افزایش دانش در کودکان نیست. هر دو متغیر تحت تأثیر سن کودک قرار دارند. مثال دیگر تعداد آتشنشانانی است که در مهار آتشسوزی شرکت میکنند و میزان خسارت ناشی از آتشسوزی است. در اینجا دوباره متغیر سومی یعنی حجم آتشسوزی است که بر روی هر دو متغیر اثر میگذارد.
در برخی موارد هم روابط جعلی کاملاً تصادفی هستند و هیچ ارتباطی به متغیر سوم ندارند. برای مثال بین تعداد پرتاب فضاپیماهای غیرتجاری در دنیا و تعداد فارغالتحصیلان دکترای رشته علوم اجتماعی در آمریکا در هر سال همبستگی قوی (ضریب همبستگی ۰٫۷۹) وجود دارد (شکل-۵).
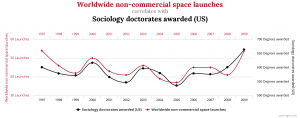
اینها مواردی از روابط جعلی بین متغیرها هستند. این مثالها خیلی سرراستاند. ولی در مسائل عملی ممکن است تشخیص آن به همین راحتی نباشد. بهخصوص حالتی که متغیر سومی ممکن است عامل پیش برنده هر دو متغیر باشد. برای مواجهه با این مسئله، طراحی دقیق آزمایش تجربی، جمعآوری دقیق داده، استفاده از روشهای کنترل آماری و بهرهگیری از چندین منبع دادهای برای تائید نتایج میتواند مفید باشد.
منابع:
Cook, T. D., Campbell, D. T., & Shadish, W. (2002). “Experimental and Quasi-Experimental Designs for Generalized Causal Inference”, Boston: Houghton Mifflin
Pearl, J., Glymour, M., Jewell, N. P. (2016). “Causal Inference in Statistics”, Wiley & Sons Ltd
Smith, G. (2014). “Standard Deviations: Flawed Assumptions, Tortured Data, and Other Ways to Lie with Statistics”, Overlook Duckworth, Peter Mayer Publishers, Inc. New York
Vigen, T. (2015). “Spurious Correlations”, Hachette Books